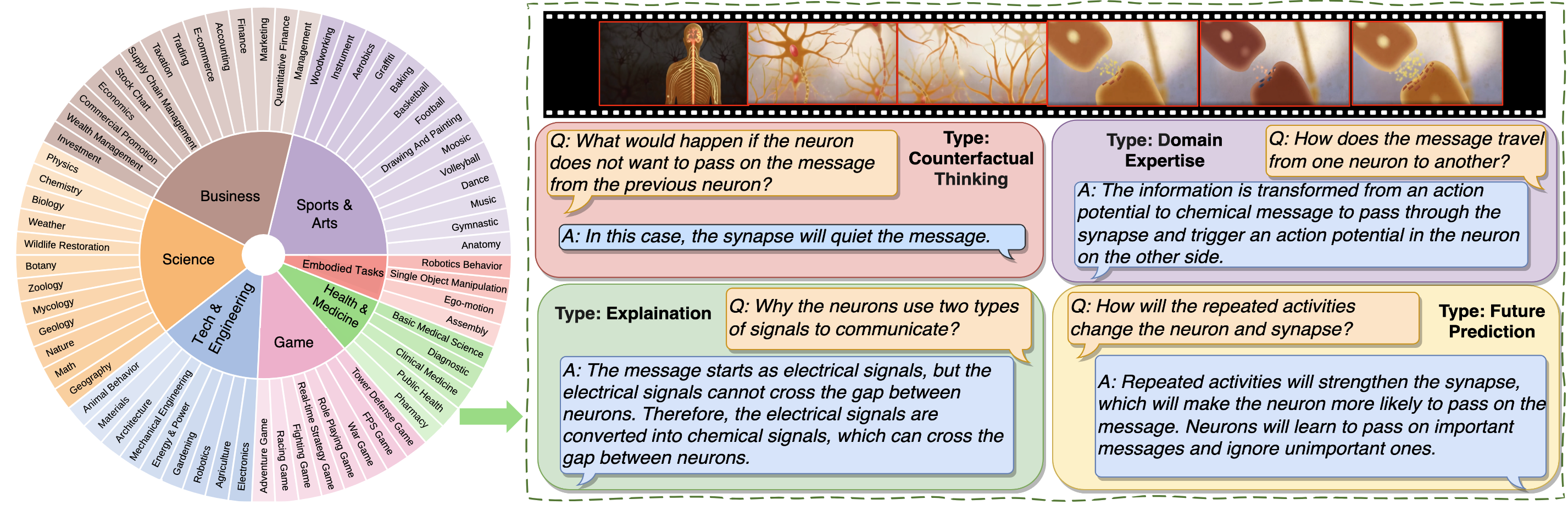
 Question Types Distribution
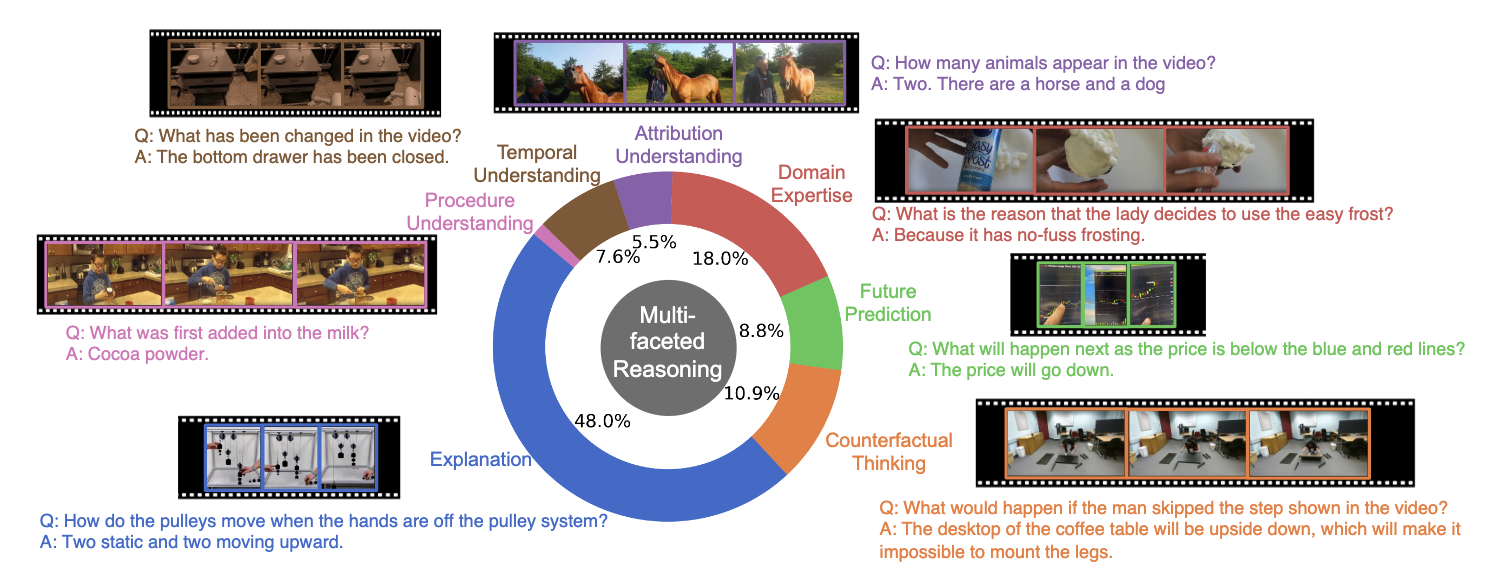
Question Types Distribution
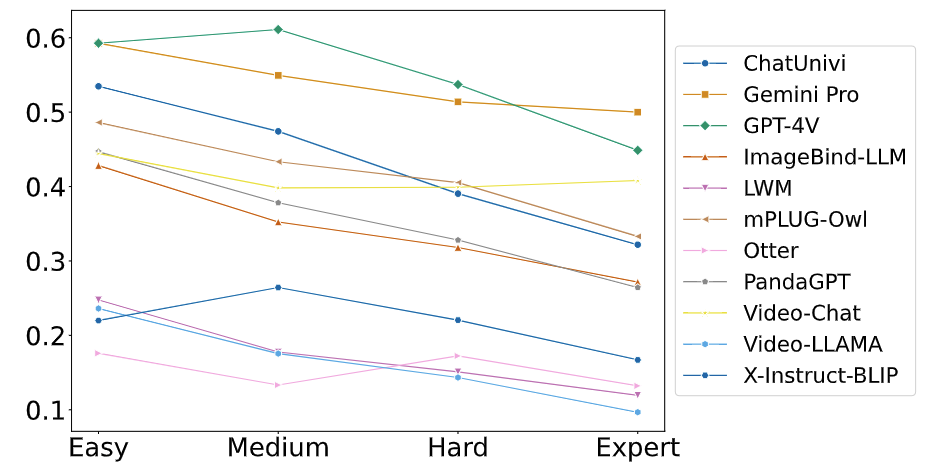
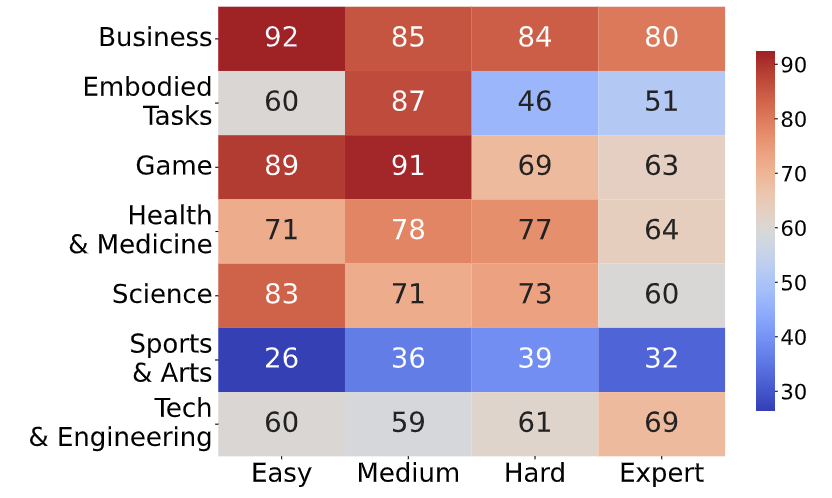
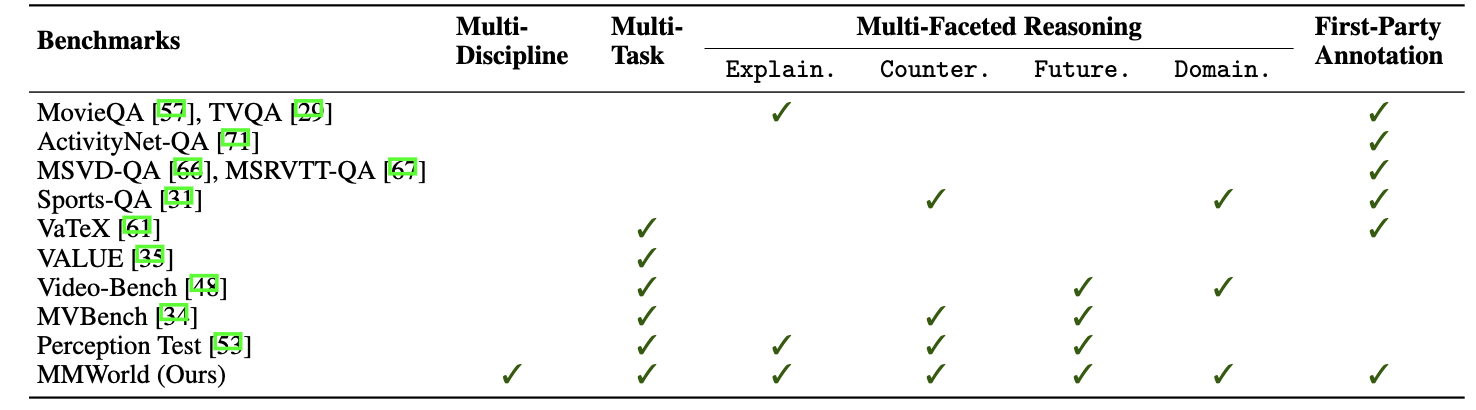
Below we shows the current leaderboard of MMWorld based on results on the human annotated datasets.
| Model | Art & Sports | Business | Science | Health & Medicine | Embodied Tasks | Tech & Engineering | Game | Average | Random Choice | 25.03 | 25.09 | 26.44 | 25.00 | 26.48 | 30.92 | 25.23 | 26.31 |
|---|---|---|---|---|---|---|---|---|
| GPT-4o | 47.87 | 91.14 | 73.78 | 83.33 | 62.94 | 75.53 | 80.32 | 62.54 |
| Claude 3.5 Sonnet | 54.58 | 63.87 | 59.85 | 54.51 | 30.99 | 58.87 | 59.44 | 54.54 |
| GPT-4V | 36.17 | 81.59 | 66.52 | 73.61 | 55.48 | 61.35 | 73.49 | 52.30 |
| Gemini 1.5 Pro | 37.12 | 76.69 | 62.81 | 76.74 | 43.59 | 69.86 | 66.27 | 51.02 |
| Video-LLaVA-7B | 35.91 | 51.28 | 56.30 | 32.64 | 63.17 | 58.16 | 49.00 | 44.60 |
| Video-Chat-7B | 39.53 | 51.05 | 30.81 | 46.18 | 40.56 | 39.36 | 44.98 | 40.11 |
| ChatUnivi-7B | 24.47 | 60.84 | 52.00 | 61.11 | 46.15 | 56.74 | 52.61 | 39.47 |
| mPLUG-Owl-7B | 29.16 | 64.10 | 47.41 | 60.07 | 23.78 | 41.84 | 62.25 | 38.94 |
| VideoChatGPT-7B | 26.84 | 39.16 | 36.45 | 53.12 | 36.60 | 41.49 | 36.55 | 33.27 |
| PandaGPT-7B | 25.33 | 42.66 | 39.41 | 38.54 | 35.43 | 41.84 | 40.16 | 32.48 |
| ImageBind-LLM-7B | 24.82 | 42.66 | 32.15 | 30.21 | 46.85 | 41.49 | 41.37 | 31.75 |
| X-Instruct-BLIP-7B | 21.08 | 15.85 | 22.52 | 28.47 | 18.41 | 22.34 | 26.10 | 21.36 |
| LWM-1M-JAX | 12.04 | 17.48 | 15.41 | 20.49 | 25.87 | 21.99 | 11.65 | 15.39 |
| Otter-7B | 17.12 | 18.65 | 9.33 | 6.94 | 13.29 | 15.96 | 15.26 | 14.99 |
| Video-LLaMA-2-13B | 6.15 | 21.21 | 22.22 | 31.25 | 15.38 | 19.15 | 24.90 | 14.03 |
Open-Source
Proprietary
More models are coming.